
Integrating RAG with Knowledge Graphs: A New Era of Context-Aware AI Responses
|
Getting your Trinity Audio player ready...
|
Summarise this article with chatGPT
Artificial intelligence is evolving rapidly, and today’s AI systems must operate in environments rich with both unstructured content and highly organised domain knowledge. Retrieval-Augmented Generation (RAG) frameworks have emerged as a powerful solution in this context, while knowledge graphs (KGs) offer a way to represent complex relationships between data points. Combining these two methodologies creates context-aware AI responses that are significantly more accurate and relevant. In this post, we explore how integrating RAG and knowledge graphs bridges the gap between unstructured retrieval and structured semantic information. We’ll cover the underlying architectures, embedding strategies, powerful tools like LangChain and Neo4j, and real-world applications in semantic SEO, customer support, and enterprise knowledge systems.
Introduction: Why Combine RAG and Knowledge Graphs?
AI systems have traditionally struggled with generating responses that consistently match both the domain context and the specific queries they receive. Unstructured data retrieval modes, even when powered by state-of-the-art large language models (LLMs), fall short when tasked with nuanced queries or domain-specific contexts. Here is where combining Retrieval-Augmented Generation (RAG) with knowledge graphs becomes particularly compelling.
By integrating RAG’s ability to fetch relevant content from unstructured sources with the structured, semantic-rich relationships housed in knowledge graphs, organisations gain an AI system that:
- Offers improved contextual understanding
- Reduces hallucination rates by incorporating verified domain knowledge
- Delivers industry-specific responses that blend narrative fluency with factual accuracy
Recent frameworks like KG-RAG have demonstrated a reduction in hallucination rates to 15%, significantly outperforming traditional RAG. With dramatic improvements in performance on tasks ranging from semantic SEO to complex customer support inquiries, the integration of RAG and knowledge graphs promises a new era of intelligent, context-aware AI systems.
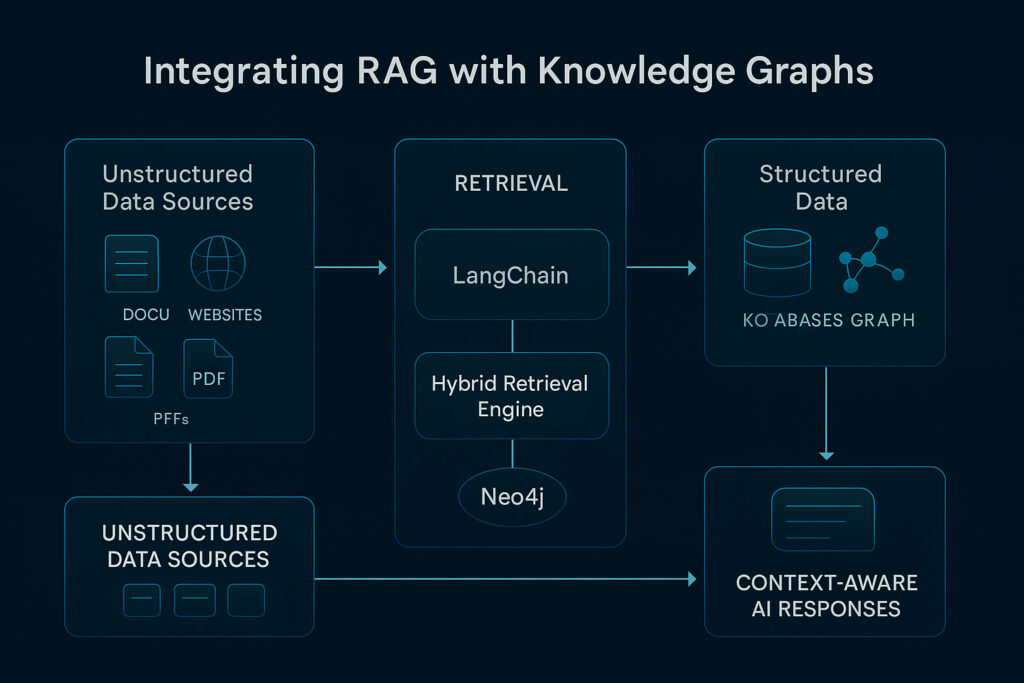
Brief Overview: RAG Architecture and Its Applications
At its core, the RAG framework is designed to enhance LLM responses by retrieving relevant external information at the time of generation. A typical RAG architecture comprises two main components:
- Retrieval Module: This segment fetches pertinent texts or document segments from a large data corpus based on the input query. This module often leverages dense vector retrieval mechanisms or utilises external search engines.
- Generation Module: Once the relevant information is gathered, the language model incorporates this data into its response, providing more accurate and context-aware content.
A growing body of research highlights RAG’s transformative potential. For instance, the WeKnow-RAG model successfully integrates web search and knowledge graphs, enabling models to utilise both unstructured and structured data for improved factual accuracy.
Similarly, the DSRAG framework shows promise in specialised industries. It constructs a multimodal knowledge graph designed explicitly around domain-specific documents, which enhances the precision of responses by seamlessly integrating conceptual and instance-level data.
Applications of RAG span a wide range of industries:
Customer Support
By leveraging company-specific knowledge bases, RAG-powered systems can provide quick and contextually accurate responses to customer queries.
Enterprise Knowledge Systems
Integrating internal documents and policy manuals with RAG helps employees quickly find relevant information.
Semantic SEO
RAG models equipped with structured data can offer detailed, authoritative responses that improve search ranking and user engagement.
Understanding Knowledge Graphs in the Context of AI
Knowledge graphs are networked representations of real-world entities and their interrelationships. By mapping out connections between concepts, processes, and data points, KGs offer a level of structured semantic clarity that standalone text cannot match. For AI, this means having a reliable, verifiable source of context that ensures the generated responses are aligned with the underlying domain knowledge.
Consider how a knowledge graph might represent information in the healthcare sector. It can link symptoms to diseases, treatments to conditions, and even associate patient profiles with historical outcomes. When integrated with a RAG system, such a knowledge graph allows an LLM to generate medical advice or research summaries that are both nuanced and accurate—a monumental leap forward from purely text-based systems.
The process of building a robust knowledge graph involves:
Data Integration
Consolidating information from multiple structured and unstructured sources.\n• Semantic Modelling: Defining the types of relationships (e.g., hierarchical, associative) between data points.
Continuous Updating
Ensuring accuracy and currency through automated data feeds or manual curation.
By embedding these structured relationships into RAG pipelines, organisations can significantly reduce errors like hallucinations—where models generate incorrect data—and enhance both the relevance and authority of AI responses.
The Role of Semantic Embeddings in Unifying Structured and Unstructured Data
One of the critical challenges for AI systems is managing both unstructured text and the more rigorously defined data found in knowledge graphs. Semantic embeddings provide a solution by transforming data—regardless of its format—into vectored representations that capture meaning and context.
Semantic embeddings translate words, phrases, and even entire documents into multidimensional vectors, enabling computation of similarities and relevance with high precision. In the context of integrating RAG with knowledge graphs, these embeddings play several crucial roles:
Bridging Modalities
They create a common framework where unstructured text and structured graph data can be directly compared, merged, and analysed.
Improving Retrieval
Embeddings allow RAG systems to fetch not only exact keyword matches but also contextually relevant content. This substantially enhances the quality of the retrieved documents.
Enhancing Reasoning
By incorporating embeddings generated from knowledge graphs, AI models gain access to a deeper layer of semantic understanding, which is vital for multi-hop reasoning tasks—a key factor in frameworks like GFM-RAG and GRAIL.
Integration of semantic embeddings is not trivial and requires a careful calibration of vector spaces to ensure that the bridge between unstructured and structured data is robust. The use of embedding strategies enhances the LLM’s capability to not only recall factual data but also provide explanations, recommendations, and decision summaries based on reliable internal knowledge.
Architecture Blueprint: Integrating Knowledge Graphs with RAG Pipelines
Building an integrated system that combines RAG and knowledge graphs involves a multi-layered architecture where each component dynamically interacts with the others. Here’s a conceptual blueprint to guide the development of such systems:
Data Ingestion and Preprocessing
- Assemble your data sources including unstructured content (web pages, documents) and structured data (databases, existing knowledge graphs).
- Preprocess the data to normalise, clean, and structure it. Techniques such as tokenisation, entity recognition, and data deduplication are critical at this stage.
Semantic Embedding Generation
- Convert both text and graph structures into semantic embeddings using robust algorithms such as BERT, GPT-based embedding models, or specialized graph neural networks.
- Ensure that these embeddings are stored within a compatible vector database, as this will facilitate rapid similarity searches.
Integration Layer: Bridging RAG with KGs
- Create an integration module that allows the retrieval engine to dynamically access the knowledge graph. This involves combining vector-based search results with graph-based reasoning.
- Techniques such as hybrid retrieval—where a query is routed through both dense vector searches and structured graph queries—are essential. The LangChain-Neo4j integration is a prime example here, leveraging both LangChain’s flexibility and Neo4j’s graph capabilities.
Query Processing and Dynamic Routing
- Implement a routing mechanism using LangChain agents that can decide which chain or tool to use based on the specific attributes of the query.
- This dynamic selection of tools ensures that the final response benefits from both the depth of text retrieval and the structured, factual grounding provided by knowledge graphs.
Response Generation and Feedback Loop
- The generation module then synthesises the retrieved information, integrating context from both text and KG-based results.
- Continuously refine the retrieval and generation pipelines by monitoring the system’s performance, thus ensuring that the AI learns and adapts over time.
By orchestrating these stages into one cohesive pipeline, developers can create systems that significantly enhance the quality of AI-generated responses while maintaining high levels of context accuracy.
Tools and Frameworks: LangChain, Neo4j, LlamaIndex and Beyond
Several tools and frameworks have emerged that simplify the process of integrating RAG with knowledge graphs:
LangChain
Known for its flexible template-driven approach, LangChain is a favourite tool for developing RAG-based applications. The recently released LangChain-Neo4j package exemplifies how the tool can integrate seamlessly with graph databases, enabling dynamic query handling and retrieval enhancements.
Neo4j
This graph database provides native vector search capabilities and robust graph-based querying with the Cypher language. It is particularly effective when paired with LangChain, enabling developers to build interfaces that query large-scale knowledge graphs efficiently.
LlamaIndex
While not as widely publicised as LangChain or Neo4j, tools like LlamaIndex offer developers another way to interface with, and extract insights from, large data corpora, particularly in contexts where both structured and unstructured data need recognition.
Additional Frameworks
The research-driven WeKnow-RAG, DSRAG, GFM-RAG, and GRAIL frameworks collectively push the boundaries of what is possible when combining RAG with knowledge graphs. Each provides unique methods for hybrid document retrieval and graph-based reasoning—pioneering advances in semantic AI response generation.
Together, these tools enable a faster, more intuitive building process that aligns with the latest best practices in AI system development, providing developers with a rich ecosystem to create innovative solutions.
Semantic SEO Use Case: Structured Contextual Delivery for AI
One of the most exciting use cases for integrating RAG and knowledge graphs lies in the realm of semantic SEO. Modern SEO is no longer just about keyword stuffing; it requires delivering answers that are both contextually rich and semantically accurate. Here’s how such an integration benefits the SEO landscape:
Enhanced Query Understanding
- With a knowledge graph guiding the RAG system, AI responses are better able to understand the user’s search intent and deliver results that are tailored to complex queries.
- For example, when a user asks, “What are the latest trends in sustainable energy technology?” the system pulls structured data linking renewable energy sources, technological advancements, and corporate initiatives to deliver a comprehensive, reliable answer.
Reduced Hallucinations and Increased Authority
- By grounding responses in structured data from a curated knowledge graph, the system significantly reduces the risk of generating inaccurate information—a common problem in traditional LLM responses.
- This reliability builds trust with users, ensuring that the AI’s output is both authoritative and in line with current industry data.
Rich, Contextual Content
- Structured contextual delivery is essential not only for ranking higher in search engines but also for engaging users, resulting in lower bounce rates and higher conversion rates.
- Integration frameworks like KG-RAG ensure that the content is enriched with factual, well-organised information, which is critical for complex topics such as enterprise technology or scientific research.
Companies deploying semantic SEO strategies using RAG with integrated knowledge graphs can thus bridge the gap between search intent and deep technical or domain-specific knowledge. This approach leads to superior user experiences, higher engagement metrics, and ultimately, improved organic search performance.
Challenges in RAG + Graph Integration (Scalability, Relevance, Granularity)
While the benefits of integrating RAG with knowledge graphs are compelling, this approach also brings unique challenges that need careful attention:
Scalability
- Handling large volumes of data in both unstructured and structured forms can be computationally intensive.
- Efficient indexing and retrieval mechanisms—such as those provided by Neo4j’s vector search—are crucial, but ensuring scalability across distributed systems remains an ongoing challenge
Relevance and Dynamic Query Routing
- The system must continuously determine whether a query is better served by unstructured retrieval or by leveraging structured graph data.
- Developing algorithms that dynamically route queries, as seen in LangChain agent implementations, requires sophisticated decision-making heuristics to maintain high relevance.
Data Granularity
- Striking the right balance between detailed node-level information in a knowledge graph and the generalised, broad retrieval of unstructured text is complex.
- Overly granular data can lead to performance bottlenecks, while insufficient granularity might omit critical contextual clues necessary for accurate responses.
Integration Complexity
- Ensuring the smooth operation of heterogeneous systems—each with its own protocols and data formats—requires robust middleware and standardised interfaces.
- Continuous updates and maintenance of both the retrieval modules and knowledge graphs necessitate dedicated resources and monitoring.
Addressing these challenges involves a combination of intelligent architecture design, ongoing research into optimisation techniques, and leveraging industry best practices. Many of the frameworks such as GRAIL and KG-RAG are exploring innovative solutions to strike the right balance, proving that the industry is moving toward a more robust, scalable integration of these technologies.
Best Practices for Embedding and Preprocessing Knowledge Graph Data
Implementing an effective RAG and knowledge graph integration not only involves combining the right tools but also adhering to best practices for data embedding and preprocessing. Here are several key practices to consider:
Normalize and Clean Data
- Prior to integration, ensure that all data—from text documents to structured graph nodes—is standardised. This process involves removing duplicates, correcting errors, and aligning different data formats.
- Regular data audits help in maintaining consistency in the knowledge graph.
Use Consistent Embedding Models
- Choose embedding models that work well across both unstructured text and graph data. Consistency in the embedding space is crucial for seamless integration.
- Popular models include variations of BERT or GPT that have been fine-tuned on domain-specific datasets.
Maintain Synchronicity Between Data Sources
- Implement automated pipelines to regularly update the knowledge graph with the most recent information from unstructured sources.
- Synchronisation minimises errors and ensures that AI responses are always based on the latest data.
Configure Granularity Settings
- Determine the optimal level of detail required for your knowledge graph. This often involves iterative refinement: start with coarser-grained nodes and gradually add detail based on query performance.
- Use techniques such as semantic pruning to filter out less relevant information while preserving critical insights.
Monitor and Evaluate Performance
- Continuous monitoring helps identify where the integration may be falling short—for example, if certain queries consistently yield suboptimal responses.
- Incorporate user feedback loops and detailed analytics to guide iterative improvements in both the retrieval and embedding processes.
Security and Privacy Considerations
- Ensure that sensitive data is appropriately anonymised and that access to structured data within the knowledge graph is controlled. This is particularly important in enterprise or customer support environments.
- Adherence to privacy regulations and best practices is non-negotiable.
By inculcating these best practices, organisations can maximise the potential of integrating RAG frameworks with knowledge graphs. Not only will this improve the accuracy of AI-generated responses, but it will also foster trust and reliability among end users.
Conclusion: The Future of Knowledge-Augmented AI Systems
The integration of Retrieval-Augmented Generation with knowledge graphs marks a transformative leap in artificial intelligence development. By leveraging the structured semantic relationships provided by knowledge graphs alongside the flexible, context-aware capabilities of RAG systems, businesses can deliver AI responses that are both nuanced and verifiably accurate.
From improved semantic SEO performance to revolutionising customer support and enterprise knowledge systems, the combined approach opens up exciting possibilities for the future of AI. While challenges like scalability, dynamic query routing, and managing data granularity remain, ongoing innovations in frameworks and tools such as LangChain and Neo4j provide promising solutions.
As industries continue to push the boundaries between unstructured and structured data, the collaborative synergy between RAG and knowledge graphs will increasingly serve as a key differentiator. Embracing this integration today not only enhances the effectiveness of your AI systems but also sets the stage for even more sophisticated and context-aware applications tomorrow.
By understanding the architectures, embedding strategies, and practical tools at your disposal, you’re well-equipped to lead your organisation into this new era of knowledge-augmented AI responses. The future is here, and it is decidedly intelligent.
In this post, we’ve covered how integrating RAG with knowledge graphs can revolutionize context-aware AI responses. With robust architectures, streamlined embedding strategies, and an ecosystem of powerful tools, this integrated approach is paving the way for smarter, more reliable, and ultimately more human-like interactions with AI systems. Whether you’re deploying a cutting-edge semantic SEO strategy or building a robust enterprise knowledge system, the fusion of these technologies offers a proven pathway to success in today’s competitive digital landscape.