
Bridging Classical SEO and Modern AI: Operationalising Statistical Semantics for Smarter Content
Why Statistical Semantics Matters Now: From Keywords to Entities in the Age of Generative Search
The evolution of search from keyword strings to conversational, generative responses has redefined what it means to create a Search Generative Experience (SGE), AI Overviews, and knowledge graph powered engines, search now interprets meaning, not just terms. Content that ranks and surfaces across generative search depends on its semantic depth, its ability to express entities, relationships, and context coherently.
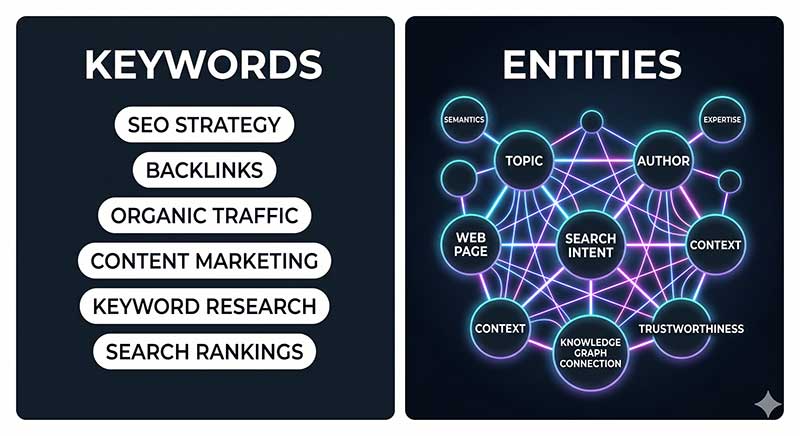
This shift makes statistical semantics essential. Techniques such as co-occurrence analysis, Pointwise Mutual Information (PMI), topic modelling, and vector embeddings reveal how ideas interrelate statistically within large datasets. These tools empower SEO professionals and content strategists to build authentic, interconnected pages that machines and humans both understand. In other words, they help bridge natural language and neural search interpretation, ensuring your pages remain visible even as ranking paradigms evolve.
Core Concepts in Statistical Semantics (Co-Occurrence, PMI/PPMI, Topic Modelling, Embeddings, Entity Salience)
Co-Occurrence and PMI/PPMI
At its core, co-occurrence analysis measures how frequently words or entities appear near each other within a corpus. When terms co-occur more often than random chance would suggest, they indicate a meaningful relationship.
Pointwise Mutual Information (PMI) formalises this by quantifying the association strength between two terms. Positive PMI (PPMI) filters out weak or negative relations, highlighting significant semantic ties.

Associate with authority on that topic.
Topic Modelling
Topic modelling methods like Latent Dirichlet Allocation (LDA) uncover hidden themes in large text collections by analysing word distribution patterns. More advanced models, such as the transformer-aided SemaTopic framework, blend contextual embeddings with probabilistic topic discovery, improving coherence and interpretability.
Used in SEO strategy, topic models reveal related content clusters you might not recognize manually, ideal for identifying subtopics and content gaps.
Vector Embeddings
Vector embeddings represent words, phrases, or documents as points in high-dimensional mathematical space, where proximity reflects semantic similarity. Models such as Word2Vec, GloVe, or sentence-transformers learn these relationships from usage context. Embeddings allow algorithms, and content teams, to measure how semantically close two ideas are, even if they use entirely different vocabulary.
Entity Salience
Entity salience measures the importance of specific entities within a text. Search engines like Google use salience to determine which entities best represent a page’s subject. By operationalising salience metrics, content teams can ensure their coverage aligns with how AI interprets topical authority.
Data In, Insights Out: Building a Semantic Corpus from SERPs, PAAs, Forums, and Docs
The foundation of statistical semantics is data. A powerful semantic corpus blends sources that mirror user language variety:
– SERP listings and AI Overviews for current dominant interpretations
– People Also Ask (PAA) questions for interrogative intents
– Reddit threads, Quora, GitHub Issues, and docs for real-world phrasing and pain points
– Competitor pages to benchmark entity and topic distributions
Use scraping and APIs (e.g., Google SERP API or Requests + BeautifulSoup) to collect text snippets, normalise them, and feed the data into tools like spaCy or Gensim for tokenisation and analysis. The corpus becomes your sandbox for calculating PMI, training embeddings, and running BERTopic models to surface latent semantic relationships.
Query and Topic Clustering with Embeddings for Intent and Topical Map Design
Query embeddings allow you to cluster semantically similar search terms, even those without lexical overlap. By converting questions and keywords into vectors using sentence-transformers or OpenAI embeddings, you can group them into clusters that represent shared search intent.
Workflow Summary:
- Generate embeddings for all collected queries.
- Perform dimensionality reduction (e.g., UMAP or PCA).
- Apply HDBSCAN or K-means clustering.
- Label each cluster around the dominant entity or problem statement.
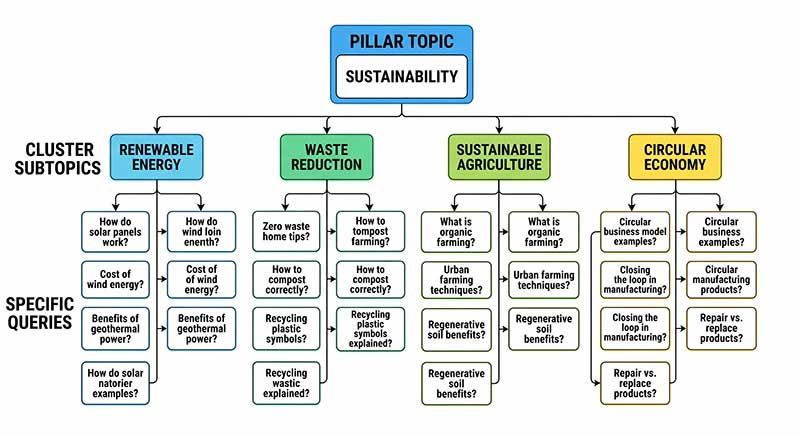
- Map clusters into a content hierarchy, pillar (broad topic) | cluster (subtopic) | spoke (specific query).
The outcome: a topical map driven by real semantic similarity rather than subjective keyword grouping.
Entity-First Content Briefs: From Co-Occurrence Signals to Required Questions and Evidence
An entity-first content brief centres on the network of entities relevant to a topic, not just keywords.
Building one involves:
- Extracting core entities using spaCy’s NER or Google Cloud NLP.
- Analysing PPMI scores to discover which entities co-occur most frequently with your primary entity.
- Listing supporting questions derived from PAA data and forums that mention those entities.
- Identifying trustworthy knowledge sources (academic papers, recognised organisations) for evidence.
This process ensures every page directly addresses the key entities and relationships the search ecosystem expects. Entity alignment enhances both human comprehension and AI interpretability.
Structuring Content for Machines: Schema.org, SameAs, and Lightweight Knowledge Graph Alignment
Text alone is no longer enough. Structuring content with schema markup and knowledge graph alignment gives search engines explicit cues about meaning.
Practical steps:
– Implement Schema.org types (e.g., Product, FAQ, HowTo, Article) aligned to content type.
– Connect entities via “sameAs” properties linking to Wikipedia, Wikidata, or your brand’s internal glossary.
Internal Linking by Semantic Proximity: Using Embedding Similarity and PMI to Shape Site Architecture
Traditional internal linking relied on navigation categories. Semantic linking reshapes this around meaning.
Methodology:
- Generate document embeddings for each URL.
- Compute cosine similarity between pages to identify closely related topics.
- Use those similarity scores to recommend contextual internal links.
Bonus tip: integrate these links naturally within content, not just in footers or sidebars, to provide genuine reader value and signal hierarchical relationships.
On-Page Optimisation Without Stuffing: Semantic Coverage, Context Windows, and Salience Tuning
Modern on-page SEO isn’t about stuffing synonyms; it’s about achieving semantic coverage.
Semantic coverage refers to how completely your content touches the entities, attributes, and questions that constitute a topic’s meaning.
Context windows, the textual regions around key entities, should contain coherent, varied supporting information.
To tune salience:
– Repeat entities naturally within unique contexts.
– Summarize frequently mentioned co-occurring entities to boost topical density organically.
Auditing salience via Google’s Natural Language API or spaCy similarity scoring helps you quantify authenticity rather than repetition.
Tooling Stack: spaCy, Gensim, BERTopic, sentence-transformers, Neo4j, and Vector Databases
Open-source tools make statistical semantics operational:
– spaCy: Named-entity recognition, POS tagging, and dependency parsing.
– Gensim: LDA topic modelling and word vector training.
– BERTopic: Topic extraction combining transformers with clustering.
– sentence-transformers: Generate robust embeddings for queries and paragraphs.
– Neo4j: Stores internal knowledge graphs and relationships.
– Vector databases like FAISS or Pinecone: Power fast semantic similarity searches and retrieval-augmented evaluation.
Integrate these tools in workflows that cycle from data gathering | modelling | insights | optimisation.
Evaluation Framework: Semantic Coverage Scores, Entity Recall, Rank and CTR Trends, and AI Overview Presence
Quantification moves semantics from theory to performance metrics.
Measure:
– Semantic coverage score – ratio of detected relevant entities vs. benchmark corpus.
– Entity recall – percentage of high-salience entities successfully covered.
– AI overview presence & CTR – indicators of visibility in generative summaries.
– Rank volatility – to track stability in topical authority.
Regular evaluations help ensure your optimisations genuinely improve understanding and visibility, not just keyword counts.
RAG for SEO Research: Safer Retrieval, Citation Policies, and Hallucination Guardrails
Using retrieval-augmented generation (RAG) to summarise or analyse semantic corpora is powerful, but risky if unmanaged.
Always:
- Source content from verified domains.
- Provide citations within generated summaries.
- Implement retrieval confidence thresholds to block hallucinated data.
Pitfalls and Ethics: Over-Optimisation, Concept Drift, Data Leakage, and Transparency
As with any data-driven framework, balance precision with trust.
– Over-optimisation can distort natural writing. Write for meaning, not for metrics.
– Concept drift occurs when topic modelling data grows outdated, refresh corpora quarterly.
– Data leakage (mixing evaluation and training data) skews performance readings.
– Transparency is vital: document data sources, tool settings, and optimisation rules for auditability.
Ethical rigor separates legitimate semantic SEO practices from manipulative generation tactics.
Implementation Checklist and Reusable Templates
|
Phase |
Key Tasks |
Tools |
|
Data Collection |
SERPs, forums, docs scraping |
BeautifulSoup, APIs |
|
Entity Extraction |
Named-entity recognition |
spaCy |
|
Topic & Cluster Analysis |
Embeddings + clustering |
BERTopic, sentence-transformers |
|
Content Brief Creation |
Entity-first mapping |
Sheets, Airtable |
|
Optimisation |
Schema markup, linking |
JSON-LD, Neo4j |
|
Evaluation |
Coverage + salience audit |
Google NLP, custom scripts |
Templates:
– Entity Brief Template: [Entity], Related [Entities], Representative [Questions], [Sources/Citations], Target [Schema Types].
– Internal Linking Matrix: Page ID | Significant Neighbors (Similarity 0.85).
Conclusion: Building Durable, Entity-Rich Content Strategies with Statistical Semantics
Statistical semantics transforms SEO from artful guesswork into measurable, machine-readable architecture. By operationalizing co-occurrence analysis, PMI, and embeddings within entity-centric workflows, brands can future-proof their organic strategy against shifting algorithms and AI-generated answers.
The winners in the age of generative search won’t merely chase new features, they’ll align meaning across content, entities, and structure, creating dynamic, enduring visibility grounded in how language and knowledge truly connect.